Data management¶
As described previously, data models in ViUR are represented by inherited classes of Skeleton, which are extended to bones. The bones provide a higher abstraction layer of the data values stored in the database. This part of the training guide should introduce to the Skeletons API and how to use these data models without the modules logic. This is sometimes necessary and later integrates into the ways on how data entities are handled inside the modules.
ViUR uses the Google Datastore as the underlying database. Google Datastore is a document-oriented, scalable, transactional “NoSQL”-database. Entities are stored schema-less, and are only specified by a data kind name and a unique key, which can also be calculated with an individual encoding. This key is also the unique property used throughout the entire ViUR system to identify and reference individual data objects uniquely.
Let’s start again with the skeleton storing personal data, introduced in the previous chapter.
class PersonSkel(Skeleton):
name = StringBone(descr="Name")
age = NumericBone(descr="Age")
In ViUR, skeletons should be named after modules or usages they are used for. To easily connect a skeleton class with a module, the naming-convention with the trailing “Skel” - like above - should be used, so this is done automatically by the system. Under some circumstances, the name may differ, and can be referenced from the module otherwise, but this is not covered here right now.
The two bone assignments define the schema of the skeleton, which is extended to the pre-defined bones key, creationdate and changedate. Under some circumstances, these bones can be removed again from the skeleton by overriding None to them.
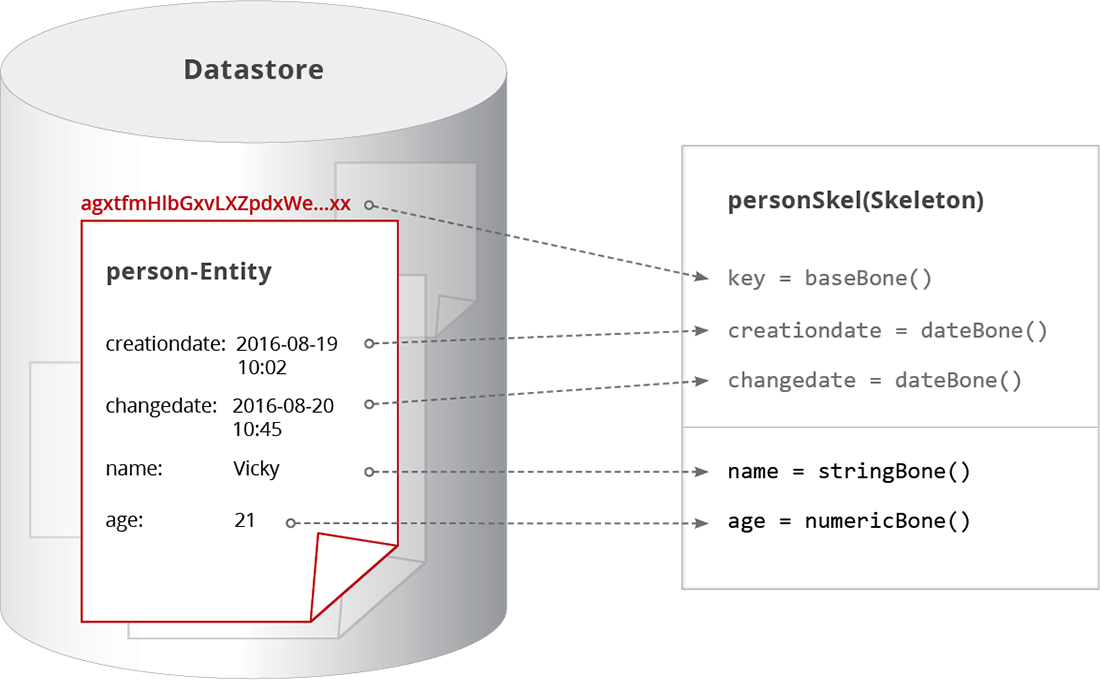
How values and keys of an entity connect to the skeleton and bones in ViUR.¶
Since bones are used to define the data model structure, they can also be marked to be filled for data integrity reasons. To do so, the required attribute must be set.
name = stringBone(descr="Name", required=True)
After that, entities with this skeleton can only be stored when at least the name field is not empty.
Adding, modifying and deleting¶
To add a data entity with the above skeleton, it first needs to be instantiated. Values are then set by using the skeleton like a dict, except that unknown keys (=bones) are raising an exception.
# get instance
skel = PersonSkel()
# set values
skel["name"] = "Vicky"
skel["age"] = 32
# write it!
skel.toDB()
# getting the key
myKey = skel["key"]
logging.info("Entity stored as %s" % str(myKey))
For storing an entity to the database, the function toDB is used. If a skeleton was not previously filled with data from the datastore using fromDB, a new key is automatically assigned.
To read an entity directly from the datastore, its key must be known. To do so, the function fromDB is used. The following code snippet loads the previously stored entity again, changes the age, and stores it back to the datastore.
# read entity into skeleton
if not skel.fromDB(myKey):
#some error handling.
logging.error("The entity does not exist")
return
# change something
logging.info(f"Current age of {skel['name']} is {skel['age']}")
skel["age"] = 33
# write entity back again
skel.toDB()
That’s it. To delete an entity, just delete needs to be called on a previously fetched skeleton, and it’ll be removed permanently.
# delete it
skel.delete()
The functions used so far:
toDBsaves an entity to the datastore,fromDBreads an entity from the datastore,deletedeletes the entity from the datastore.
Queries and cursors¶
ViUR provides powerful tools to easily query entities, even over relations.
To make bones usable within a query, the indexed attribute of the particular bones must be set in the skeleton. This is also required for attributes involved into an ordering.
class PersonSkel(Skeleton):
name = stringBone(descr="Name", required=True, indexed=True)
age = numericBone(descr="Age", indexed=True)
A query can be created from a skeleton using the all function. This default query is a selection of all entities of the given skeleton. To granulate the result of this default query, the function filter is used. It provides ways to also filter not on equality, but also on greater or lower conditions.
# create the query
query = PersonSkel().all()
query.filter("age >", 30)
# how many result are expected?
logging.info("%d entities in query" % query.count())
# fetch the skeletons
for skel in query.fetch():
logging.info(f"{skel['name']} is {skel['age']} years old")
Indexes¶
Using complex queries causes the datastore to work on index tables to find the correct entities. These index tables must be explicitly described and managed in the index.yaml file of the project. In a local development system, index definitions are automatically generated into this file when a query needs an index, and no definition for this index exists.
Doing so in the following snippet:
query = PersonSkel().all().order("name", "age")
for skel in query.fetch():
logging.info(f"{skel['name']} is {skel['age']} years old")
When executed, this yields in the following index definition in the index.yaml file. The function order, that was used above, allows to add an ordering on one ore multiple attributes to a query.
- kind: person
properties:
- name: name
- name: age
Indexes are lookup-tables, managed by the datastore. They are updated just in time when involved entities are changed, but need some time to be initially built. Therefore, an error is raised, when running a query requiring an index which does not exist or is currently established within an application running directly on the App Engine. So checking out the logs or the datastore index overview in the Google Cloud Console gives help when index definitions are missing, or errors temporarily come up right after a web application with different query attributes was deployed.
Cursors¶
In web applications, queries underlie some restrictions, which are technically not a problem, but may cause timeout problems on HTTP requests. Therefore, the use of cursors is required, and queries sometimes need to be split in deferred tasks or requested asynchronously to decrease request latency. ViUR limits its maximum request limit for dataset fetches to a maximum of 99 entities. 30 entities is the default, if no other limitation was explicitly given. This means, that not more than entities than at least 99 can be fetched per query. The query can be continued later on using a cursor.
To obtain a cursor, the getCursor function returns a proper cursor object. This can be set to the same query (means: having the same filtering and ordering) using the function cursor.
The following piece of code is an example for a function that works exactly on this mechanism. It is a deferred version of the querying example from above. This function runs, once initiated, on the server-side and fetches all entities of the persons available in the database.
@CallDeferred
def fetchAllPersons(cursor = None):
# create the query
query = PersonSkel().all().filter("age >", 30).cursor(cursor)
# fetch the skeletons
for skel in query.fetch():
logging.info(f"{skel['name']} is {skel['age']} years old")
# if entities where fetched, take the next chunk
if query.count():
fetchAllPersons(query.getCursor().urlsafe()))
Important functions used for querying:
allreturns a query to all entities of the skeleton’s data kind,filtersets a filtering to one attribute to a query,ordersets an ordering to one or multiple attributes within a query,cursorsets a cursor on a query,mergeExternalFiltercan be used as a safer alternative to apply multiple filters with an ordering from a dict with just one function call,getCursorreturns the next cursor of a query.
Relations¶
In ViUR, the relationalBone is the usual way to create relations between data entities.
The relationalBone is used to construct 1:1 or 1:N relations between entities directly, with an automatic module integration included into the admin tools. It is also possible to store additional data with each relation directly within the relation, so no extra allocation entity is required to store this information.
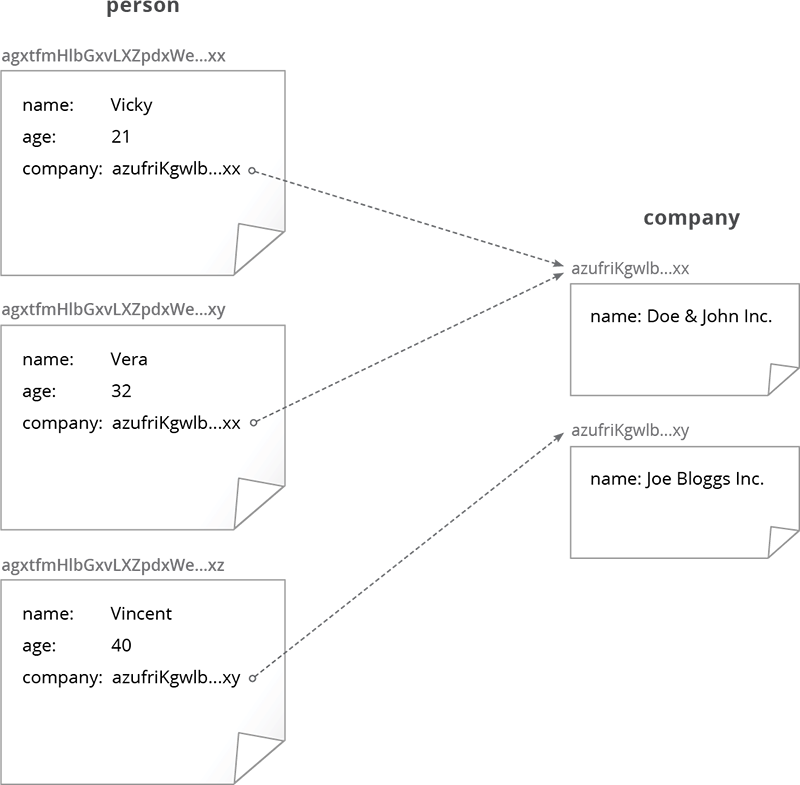
Assigning companies to persons.¶
Let’s connect the persons to companies. The figure above shows a classic 1:N relationship. Every person can be assigned to one company, one company can be referenced by several persons. For storing companies, a new skeleton needs to be introduced.
class CompanySkel(Skeleton):
name = stringBone(descr="Company name", required=True, indexed=True)
To administrate companies also with ViUR, a new module-stub needs to be created.
Then, the entity kind is connected to the person using a relationalBone.
class PersonSkel(Skeleton):
name = stringBone(descr="Name", required=True, indexed=True)
age = numericBone(descr="Age", indexed=True)
company = relationalBone(kind="company", descr="Employed at", required=True)
This configures the data model to require for a company assignment, so that entities without a company relation are invalid. Editing a person entry now again in the Vi offers a method for selecting a company and assigning it to the person.
[screenshot missing]
Although the datastore is non-relational, offering relations is a fairly complex task. To maintain quick response times, ViUR doesn’t immediatelly search and update relations when an entry is updated. Instead, a deferred executed task is kicked off on data changing, which updates all of these relations in the background. Through depending on the current load of the web application, these tasks usually catches up within a few seconds. Within this time, a search by such a relation might return stale results.